人工神经元及神经网络:
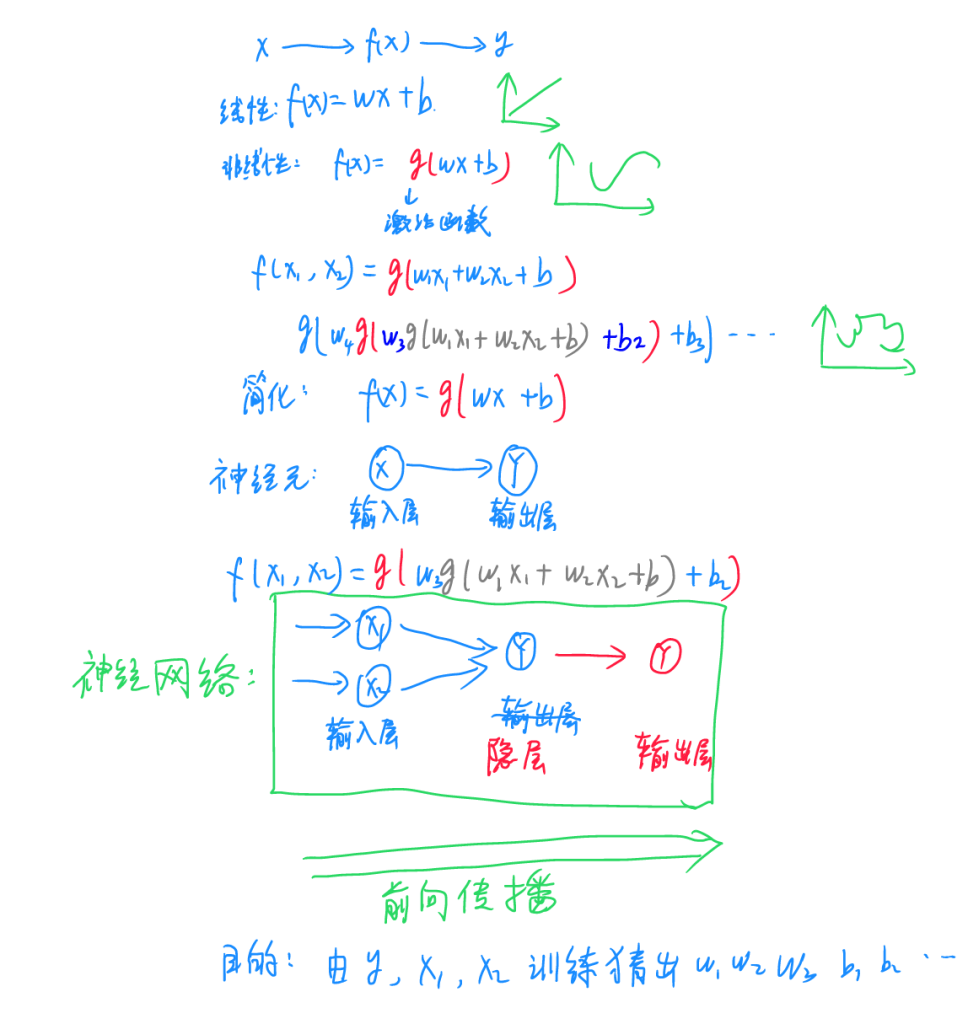
所有的神经网络无非都是一个函数操作,在这个操作中,我们输入一个或多个X,可以是文本,图像,声音,视频等等信息,希望得到对应的因变量Y,即X经过一个变换f(x)后得到y,最简单的神经网络是线性的,此处f(x)=wx+b,式中w为参数,b为偏置。由于线性的操作只能处理线性可分的数据,无法处理复杂的曲线等数据,解决方案是在线性部分外套一个激活函数。常用的激活函数都非常简单,如sigmoid函数等,但是非常好用。通过激活函数的层层嵌套,理论上可以构造任意的曲线,实现了复杂的应用需求。输入的数据不一定只有一个,可以有多个,为了简化书写,记为:
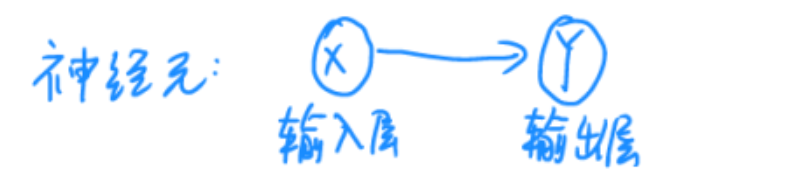
若由输入层直接输出结果,类似单层感知机结构,则此神经网络不含隐层,只有输入与输出两层。若需要在中间加一层或多层网络进行深度特征提取,中间添加的网络层在运行时不显示,故称之为隐藏层或隐层。从输入层至隐层至输出层的方向传播称之为前向传播,神经网络的训练目的就是由输入的x1,x2……xn和期望输出的结果y猜出来参数w1,w2……wn,与偏置b1,b2……bn。
损失函数与反向传播:
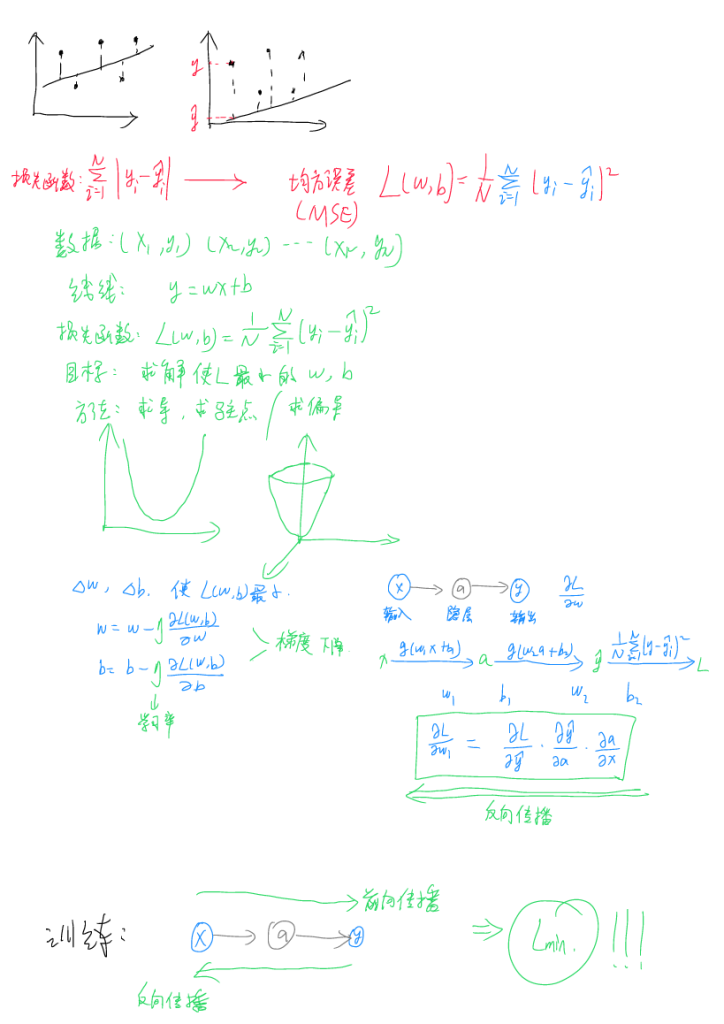
判断一次训练好不好需要一个量化的标准,我们把这个标准叫做损失函数,找到了最优的损失函数即找到了最终的参数,也就是完成了训练。使得损失函数最小的训练原理是调整拟合线使得实际数据与拟合线间的距离之和最小,由于距离是一个绝对值量,不太方便进行运算和输出,因此我们将其平方并求和,最后再除以数据总数量N以排除样本数量对训练的影响,最终我们得到了均方误差损失函数(MSE),这是比较常规也是使用比较多的评价指标。求解的最终目标就是找到使得损失函数L最小的参数w以及b(可以多个)。求解的方法即求导,由于有不止一个需要求解的量,此处需要求偏导。
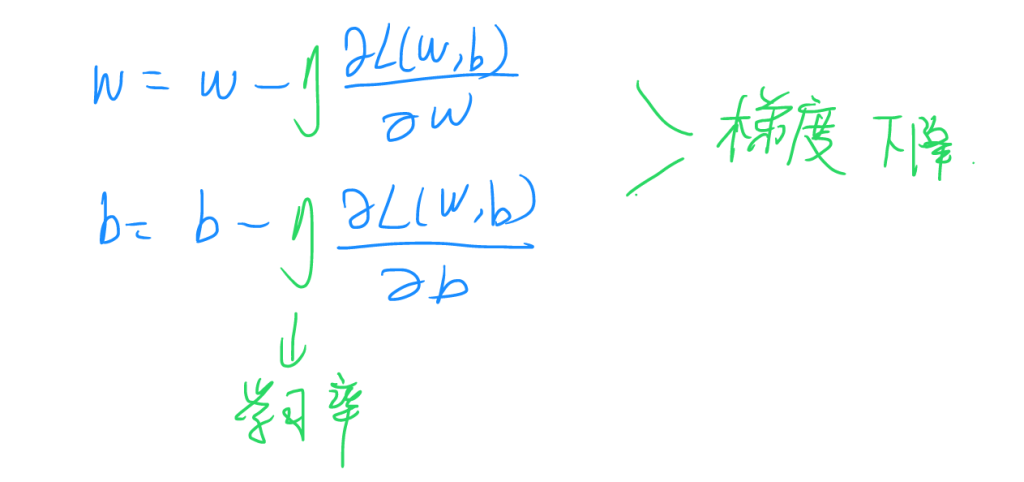
为了方便计算机计算,此处将求解式写成迭代形式,参数η为学习率,使得整个式子往梯度下降的方向调整,能够加速收敛,即可大大加快训练过程。
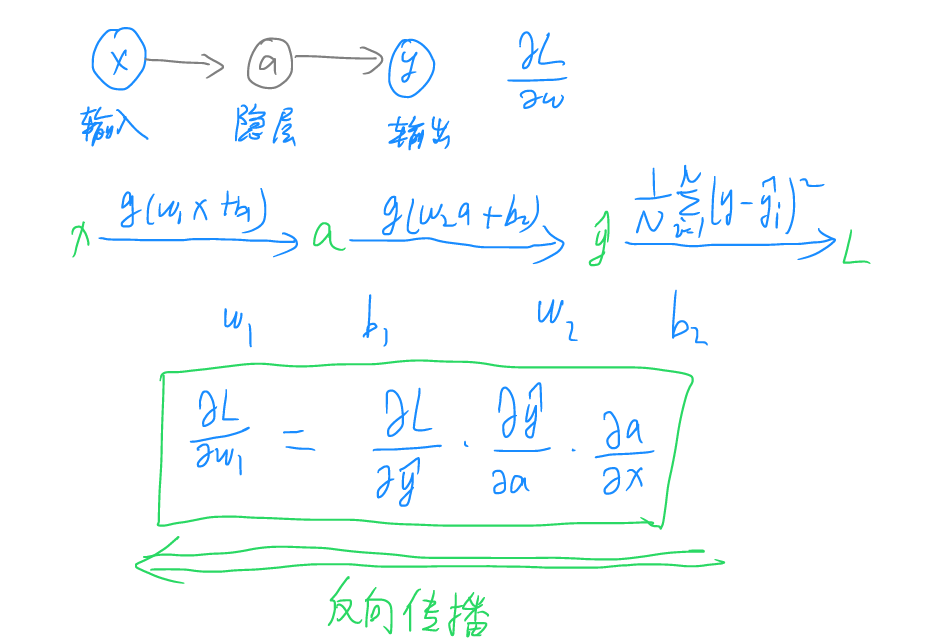
从输入至输出经过了多轮求偏导的操作,由于求偏导的过程可逆,此处可一步步反推从输入层至隐层至输出层和损失函数之间的参数,这个反推的过程称之为反向传播。
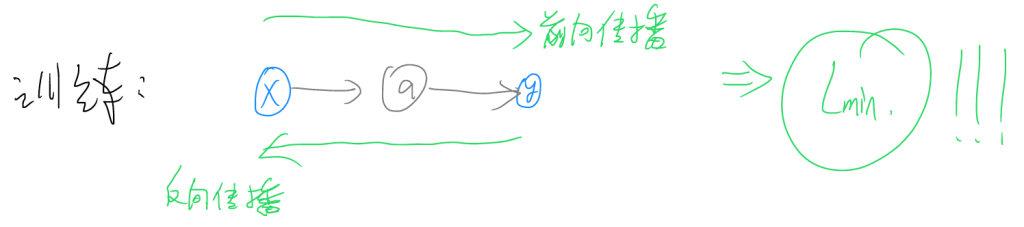
训练就是前向传播与反向传播交替进行,最终使得损失函数L最小化的过程,至此我阐述完成了训练的基本原理。
过拟合与处理方法
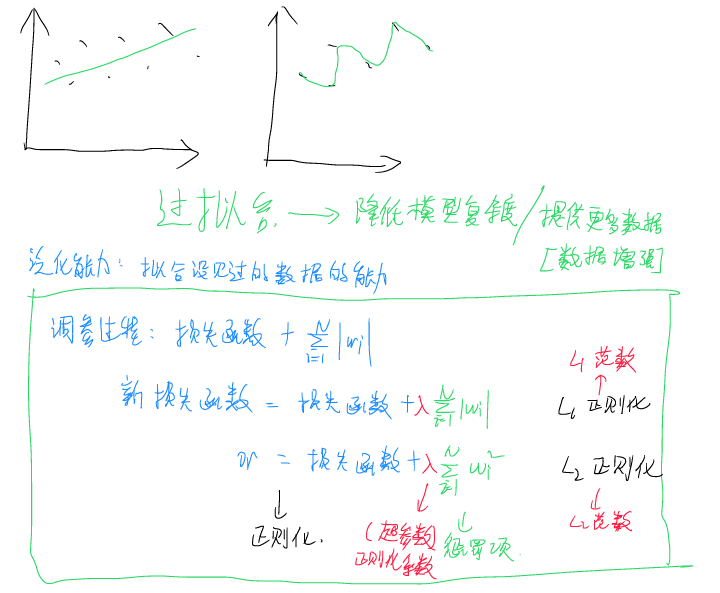
过拟合,是指模型在处理已有数据时表现优异,但处理未见过的数据时表现不佳的概念。如上图所示,其主要原因为模型复杂度过高,泛化性不足。为了避免过拟合的问题,通常我们需要进行数据增强(即提供更多数据),或者采用降低模型复杂度的方法,前者通常比较棘手,因为优质数据获取不易,而后者有时可以简单粗暴,例如提前终止训练或者使用一些正则化的手段。
正则化的过程是指在损失函数中添加已有的系数以达到使构造得到的新损失函数梯度不会太小的手段。添加项成为惩罚项,正则化系数为超参数λ。若添加的是w的L1范数,则称之为L1正则化,若为L2范数,则为L2正则化。还有其它的方法,例如Hinton提出的Dropout方法,在每轮训练时随机丢弃一部分数据,避免训练时对某些数据依赖性过大,也可以避免过拟合的现象。
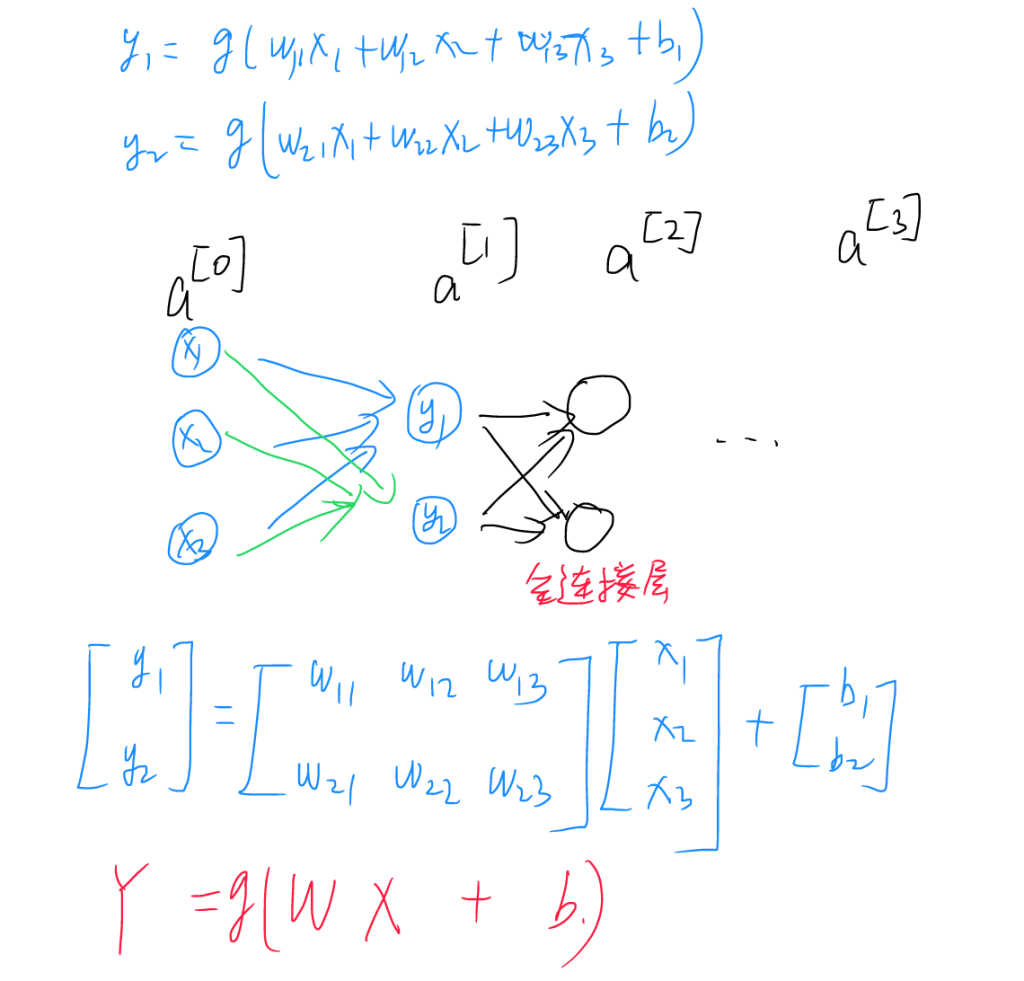
计算机在处理训练时,可以调用GPU并发运算,训练其实是以矩阵的形式进行的,即构造输入输出、系数矩阵,并通过矩阵运算。
CNN卷积神经网络
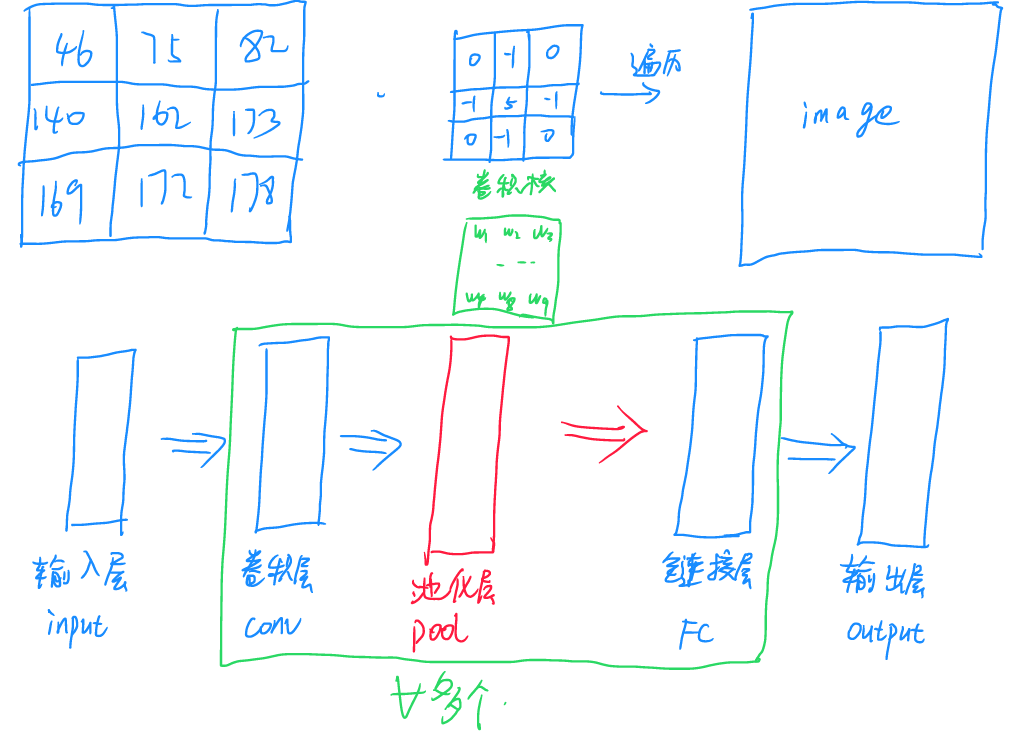
CNN卷积网络其实是对线性神经元的一个变体,可以想象把CNN拉直之后,就是线性的神经元操作,只不过我们把系数放到了一个矩阵里,依次对大矩阵内的输入值做点积,并把结果放到输出矩阵。被操作的部分数据称之为感受野,遍历过程称之为感受野平移,进行卷积的小矩阵称之为卷积核。CNN网络的训练其实就是通过训练找到所需的卷积核,需要注意的是,一些操作的卷积核是已知的,例如在ps中进行图像浮雕化操作等。
为了避免卷积过程导致矩阵越来越小,可以在卷积操作中对卷积的数据进行邻域补充,称为零填充(padding)。卷积提取局部特征后为了避免数据过大,会进行池化(Pooling)操作用于降维和特征增强,常见的池化操作包括最大值池化与均值池化等。
RNN循环神经网络
卷积神经网络可以用于处理图像信息,但是无法处理语言信息,为了实现对语言信息的处理,提出了RNN网络。
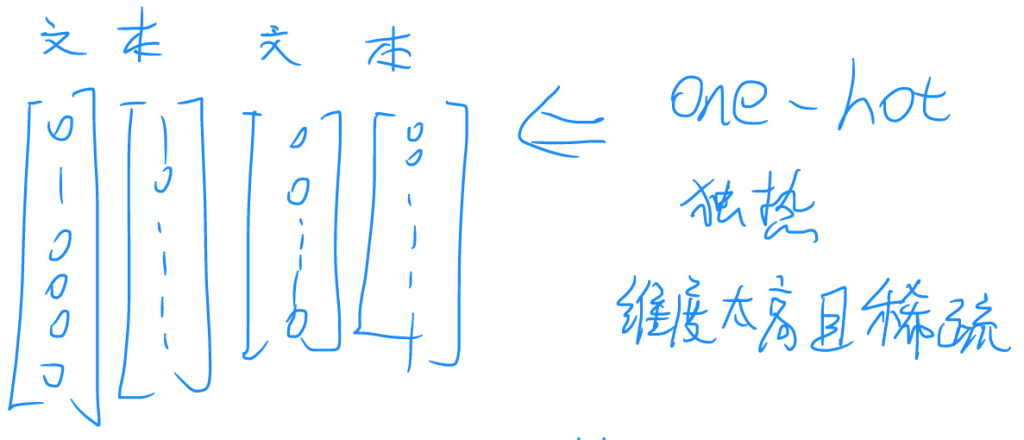
计算机无法直接输入与理解文本信息,故输入时首先需要对文本进行编码。早期的编码方式是独热编码(one-hot),这种编码的特征是为每一个文本都赋予一个向量,不同的文本间是相互正交的,因此这个编码维度超级高,且超级稀疏,矩阵密度比较低,有多少文本就需要有多少维向量,并需要相应数量的输入神经元,这显然不现实。
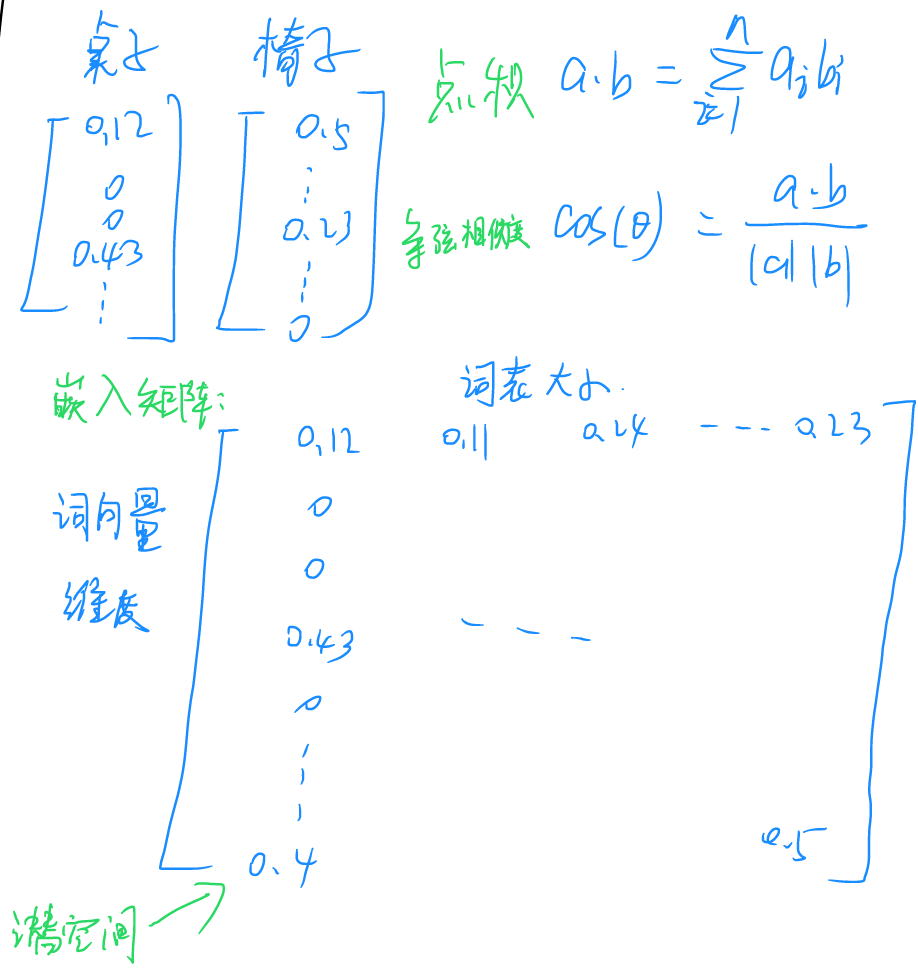
为了解决这个问题,发展了词嵌入(word embedding)技术,这种技术通过训练,将一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中。词嵌入模型词表需要经过预训练,在训练结束后可以直接在各类模型中调用,并可以通过点积与余弦相似度等操作评估此表矩阵中两个向量的关系。
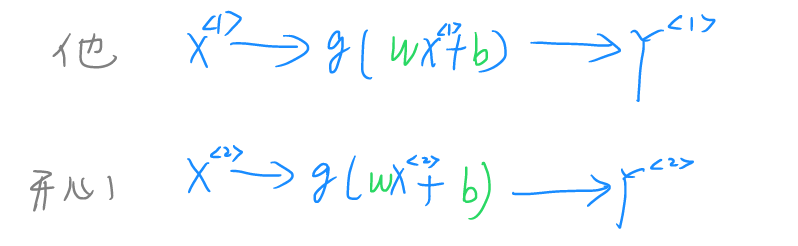
在进行不同词语的操作时,通常的操作是分别对单个词语进行神经网络运算,并得到相应的输出。这种方法不能够对两个词语之间的关系进行表示,即词与词之间没有联系,神经网络之间存在孤岛效应。
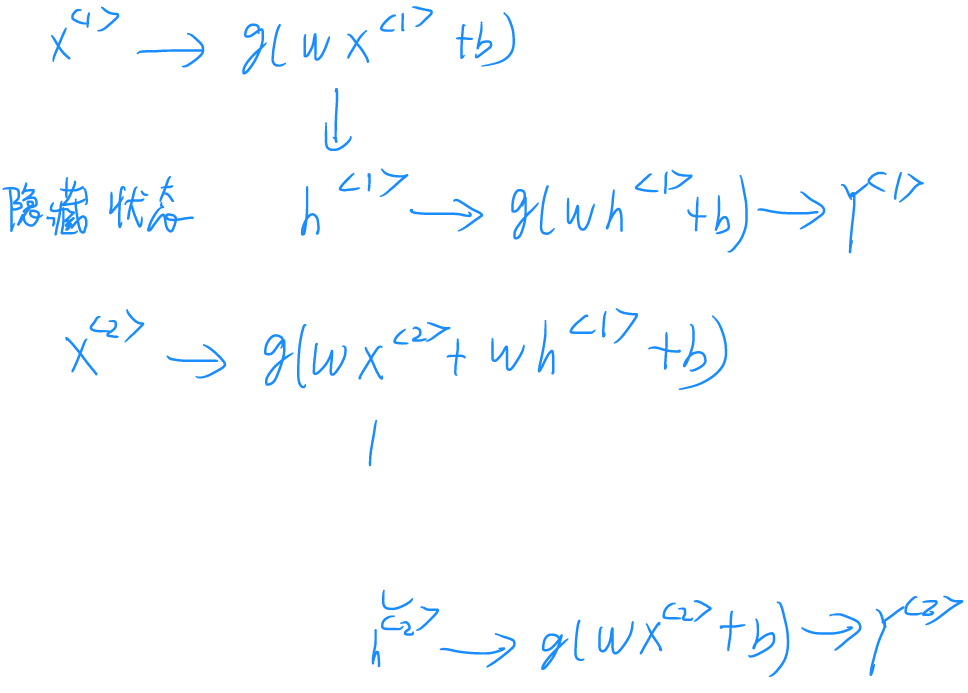
为了解决这个问题,采用如上图所示的技术,第一个词的神经网络并不直接输出结果,而是转而输出一个隐藏的中间层h1,在第二个词处理时,加入一项含有h1的权重,然后再输出第二个隐藏中间层h2……如此便可在后续词处理过程中引入前项词的信息,完成信息的流通,避免两个词之间无依赖的问题。
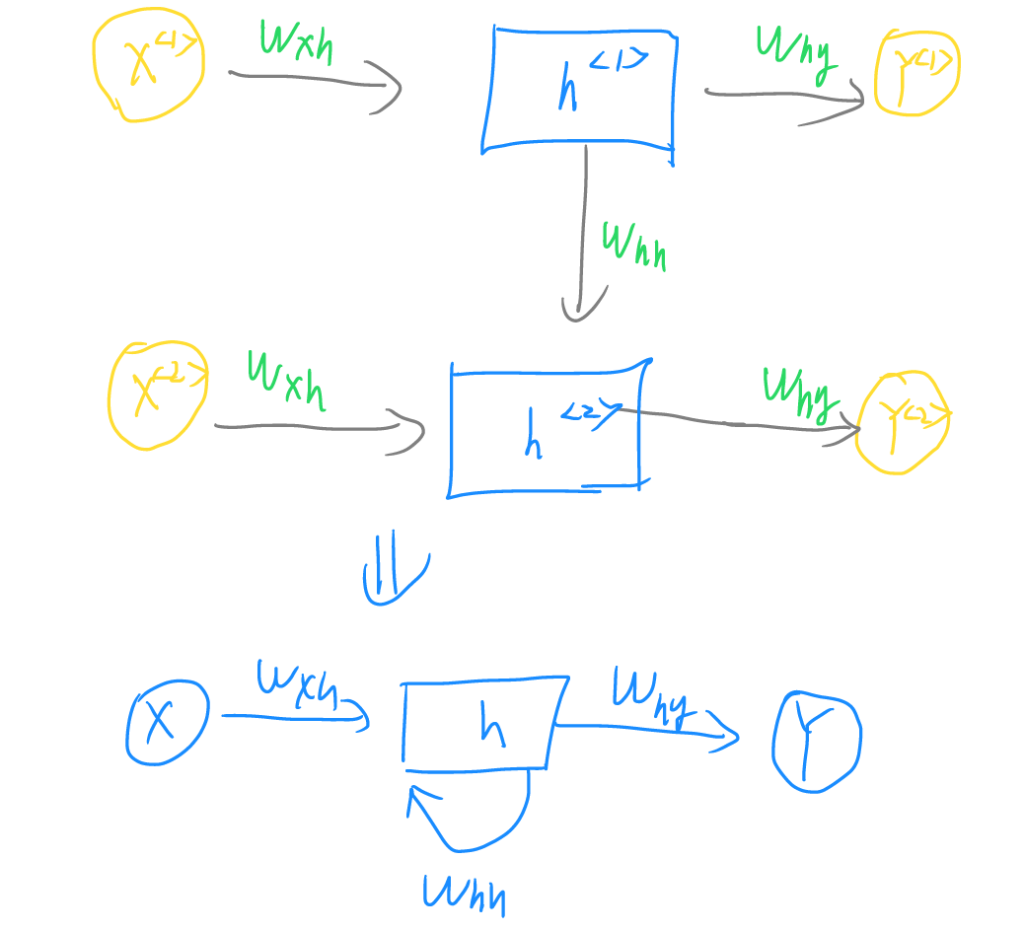
至此,完成了RNN循环网络的原理说明。然而RNN循环网络存在一些问题,例如无法捕捉长期依赖以及只能穿行计算,无法进行并行计算效率较低。针对这些缺陷,学者们进行了一些改进,例如使用LSTM遗忘门,使得RNN循环网络选择性的保留或遗忘所需前项词的信息,能够保留更多长期依赖等,但结构比较复杂,且终归无法解决穿行计算的问题,因此,亟需有一种全新的架构来简化与加快计算。
Transformer
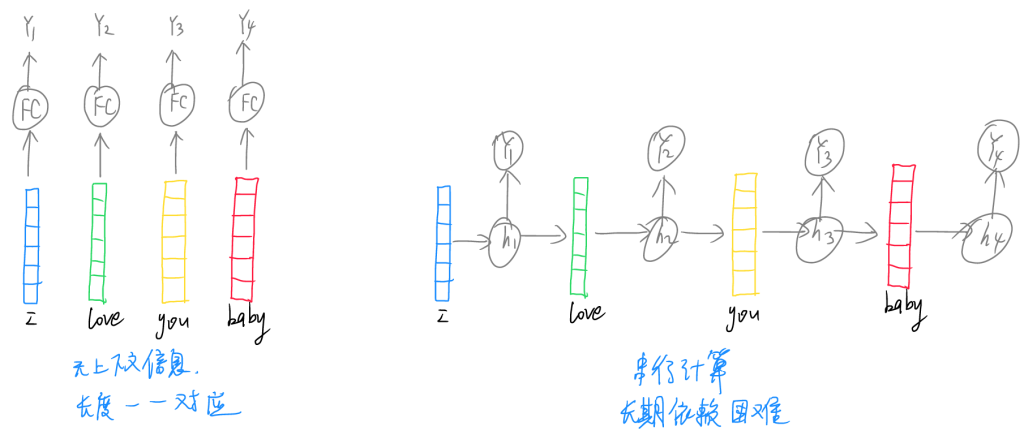
前文提及,单个词语的神经网络无上下文信息,且输入输出长度必须一一对应,这无法完成复杂的文本语言处理任务,而RNN循环网络虽然引入了上下文信息,但存在串行计算速度受限效率低且长期依赖困难的问题。后续发展的Transformer技术则能够解决这些问题,且架构简单,功能强大。
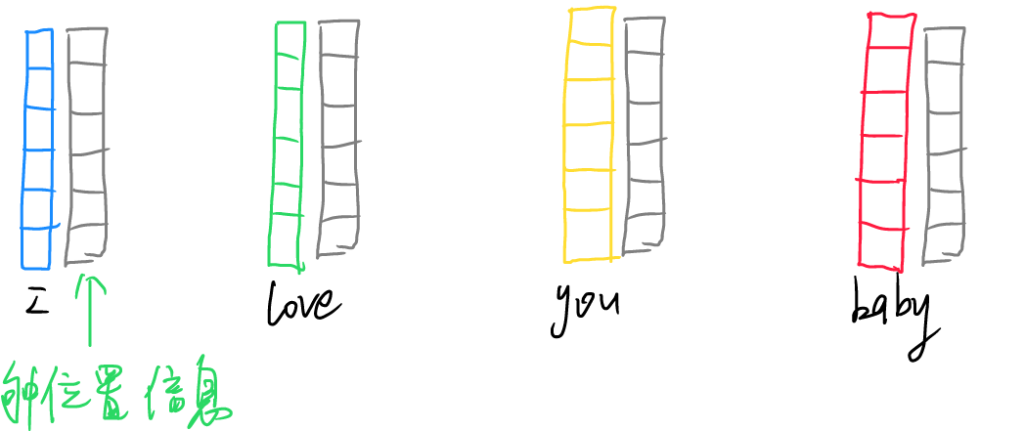
在进行Transformer运算的第一步,也是需要使用词嵌入(word embedding)技术,在词向量中嵌入位置信息,使得该词向量知道它处于什么位置。然后使用三个预训练的矩阵(Q、K、V),分别于词向量做点积运算,得到qi,ki,vi向量。其中,Query(查询)代表当前需要关注或处理的元素想要获取信息的“意愿”,用来查询其他元素与自身的相关性;Key(键)可以理解为索引信息,用来与Q匹配衡量不同词向量之间的相似程度;Value(值)则包含输入序列中每个词向量的实际信息内容,通过与Q、K的匹配结果(也就是相似度)加权求和,从而得到融合了相关信息的输出。
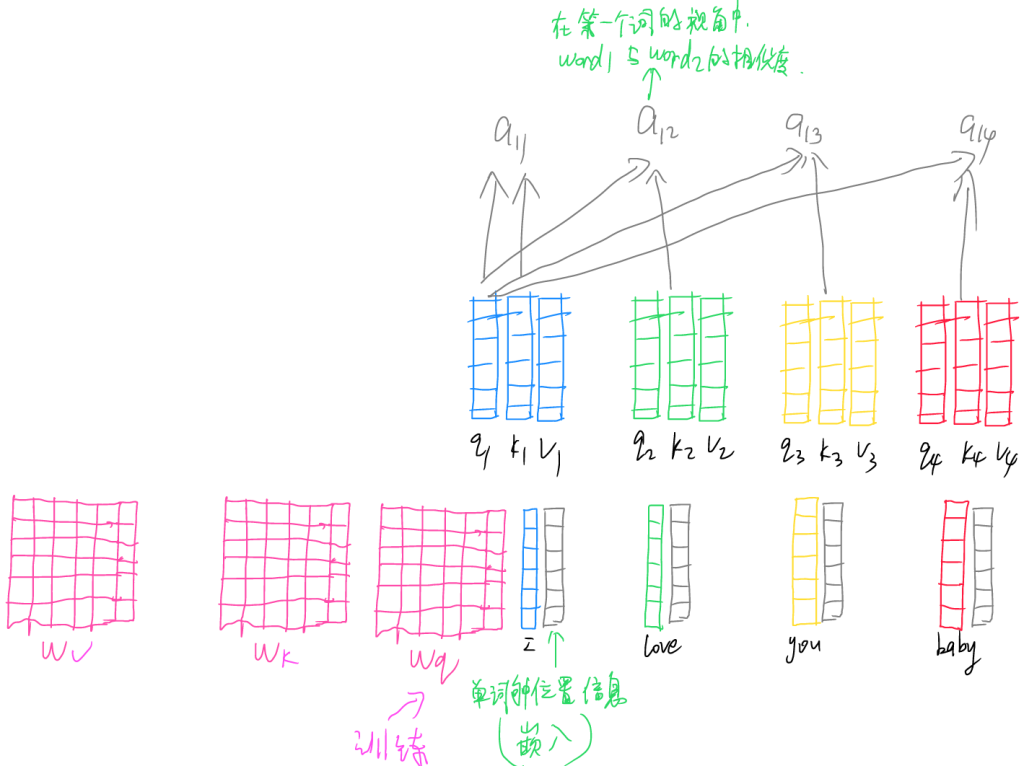
将q1与分别与k1,k2,k3分别做点积运算得到a11,a12,a13……
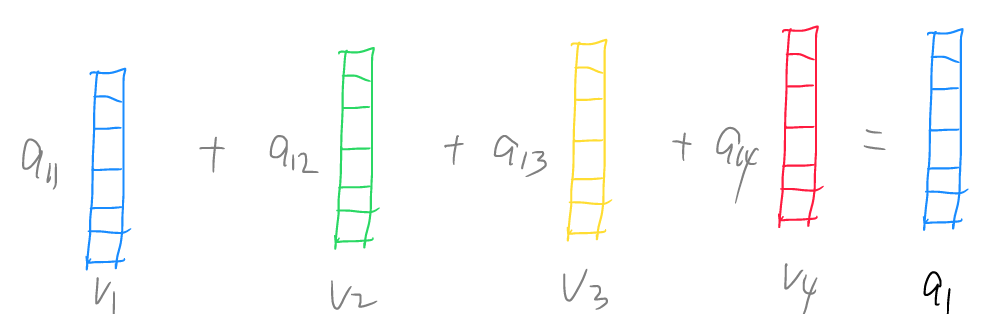
然后再分别和v1,v2……做运算,求和后就得到了包含全部语义信息的第一个词向量 a1。
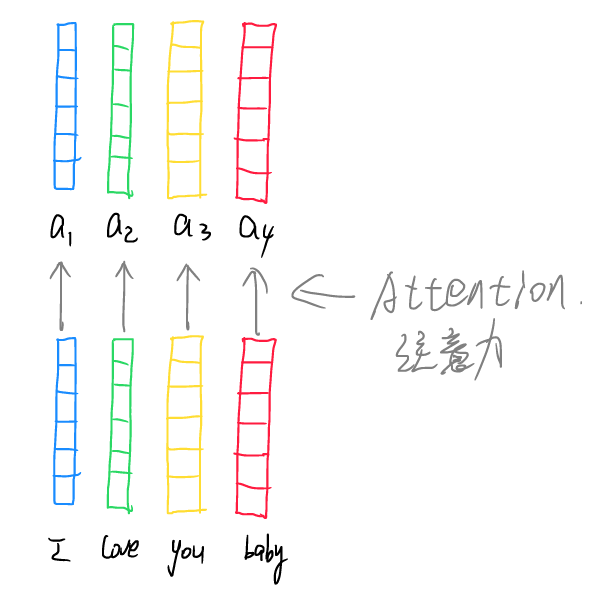
依次处理所有词向量后就能够得到所有的含有语义信息的新向量,这就是self-Attention注意力机制的原理。上述步骤中只用到了一组QKV矩阵,称为单头注意力,若用多组矩阵分别操作,则为多头注意力机制(multi-head Attention),类似从不同的角度看问题,能够更加全面地反应信息。
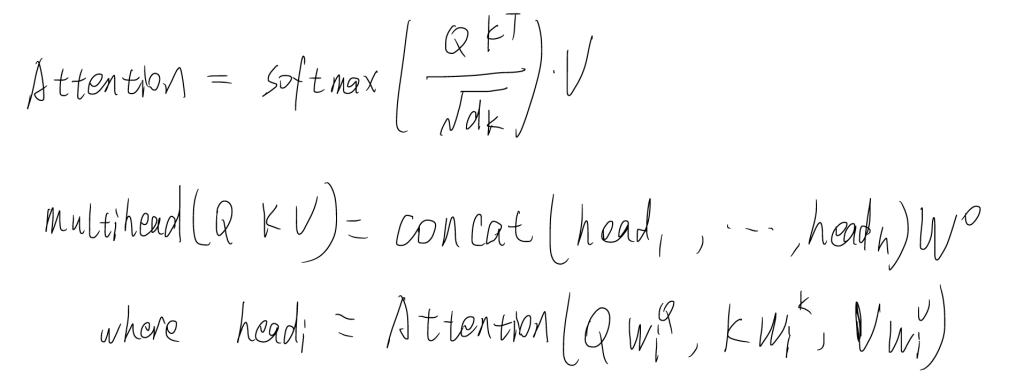
这就是Transformer中自注意力机制与多头注意力机制的原理。
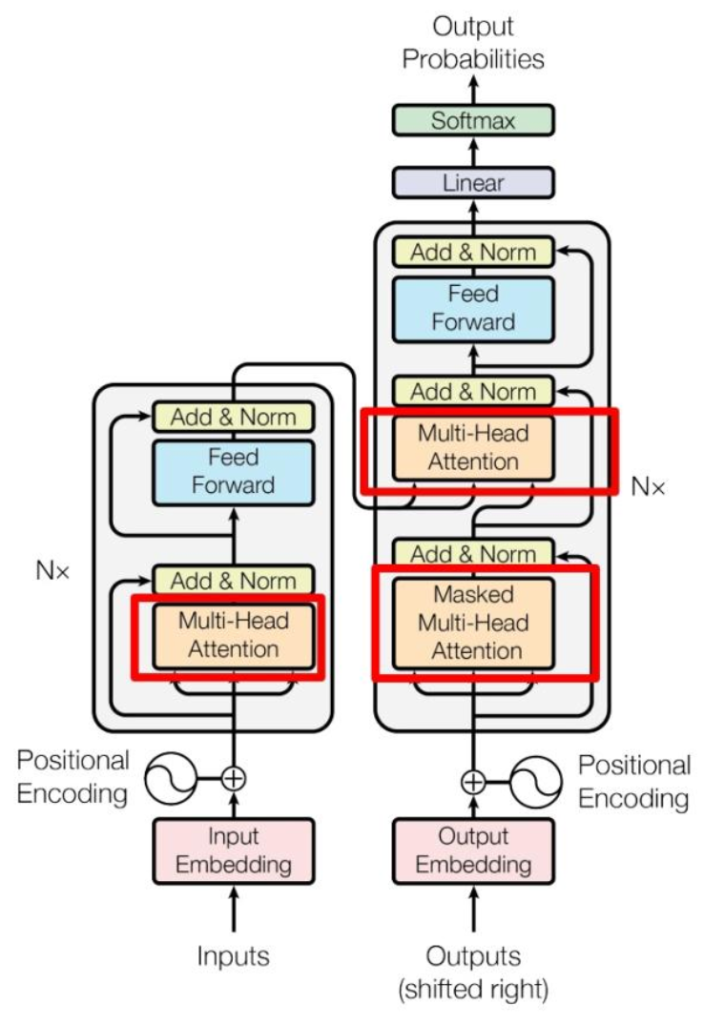
明白了多头注意力机制之后再来看这副世界名画,则层次分明,逻辑简单。输入的词向量首先经过词嵌入技术,输入编码器,编码器内进行多头注意力处理,然后经过feed forward全连接和残差连接、归一化等操作,输入解码器的多头注意力部分作为Q和K矩阵。解码器同样具有词嵌入,前置多头注意力机制,残差连接、归一化等操作,然后作为V矩阵,与含有解码器输出的Q和K矩阵一同进行多头注意力操作,随后经过feed forward全连接和残差连接、归一化,最后经过线性操作后外套softmax激活函数输出预测单词。掌握了基本的CNN,RNN,Transformer等等框架的基本原理后,可以在不同的模型中嵌套,训练,最终得到千变万化的实现不同功能的大模型,大模型在论文”Attention is all your need .”后得到了充足的发展。
多模态大模型
由于多模态大模型数量众多,此处以我熟悉的对抗式生成网络GAN与stable diffusion为例进行原理阐述。
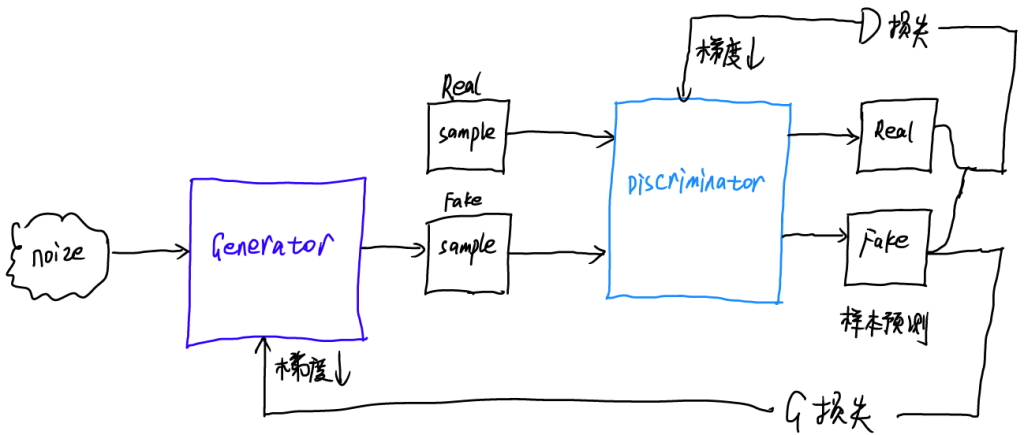
对抗式生成网络GAN主要由两个部分组成,即生成器(Generator)与判别器(Discriminator),生成器用于生成假图像,判别器用于判断生成器生成的真实性,输出真实概率。
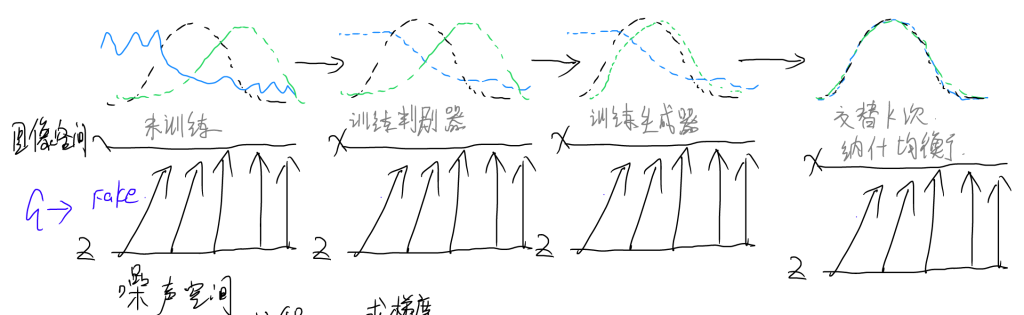
训练的过程如上图所示,由噪声空间输入噪声入图像空间,然后生成器生成假图像。训练首先在判别器上进行,在未经训练时,判别器对于生成器生成图像的真实性判断不佳,存在较大的误差,训练k次判别器后,在真实图像一侧给出高分,在生成图像一侧给出低分。随后进行一次生成器的训练,将生成图像数据分布往真实图像一侧靠近。交替训练数轮之后,二者达到纳什均衡。

如上图所示,在判别器训练过程中,生成器固定,我们的目标是使得判别器价值最大化,则在式中,判别器认为生成器生成的图像是真实数据的概率越大越好,判别器认为生成器生成图像是虚假图像的概率越小越好,对该式整体使用梯度下降算法加快收敛速度;在训练生成器时,判别器固定,故前一项可视为常数,求梯度时为零,故可以不用在式中体现。生成器和判别器的对抗式训练是一个极大极小的零和博弈,二者绝非合作式的,这一点我认为和课堂上老师讲的有一些冲突。最终两者能够完成工作是因为达到纳什均衡,生成器生成的每一张图像都十分接近真实图像,而判别器在面对每一张生成的图像都认为其为真实图像的概率为0.5。
Stable Diffusion
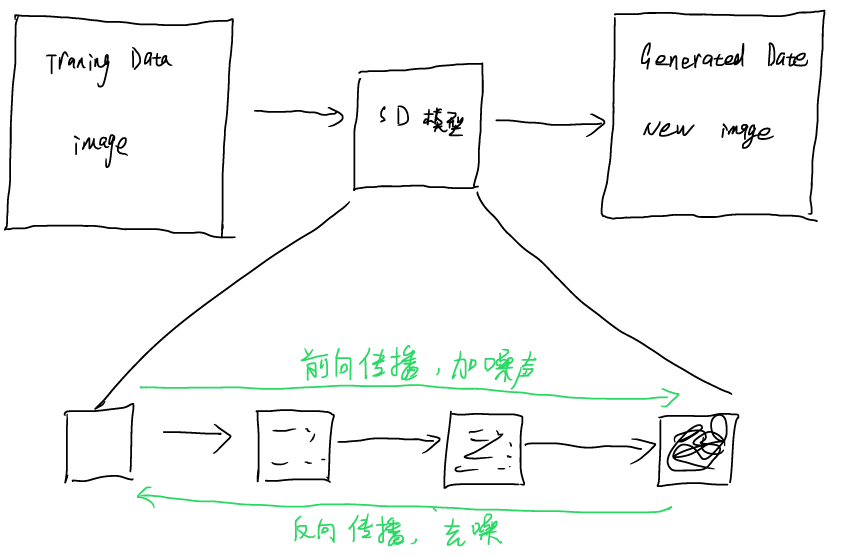
扩散模型,是比较新的模型,且效率较高,近年来得到了非常充足的应用。在扩散模型的训练过程中,HR图像首先经过逐步加噪过程,该过程可控可逆,最终得到LR图像以至于最终类似噪点的图像,此过程称之为前向传播。为了生成高清晰度图像,在训练过程中还需要对图像进行去噪,在训练时,可以对加噪过程进行逆变换,有了成熟的算法后可用于图像生成。
直接对高分辨率的图像进行变换操作对算力消耗过大,且比较耗时,因此,SD模型对图像的生成操作是在噪声空间,即潜空间内进行的,原始图像经过卷积操作,多轮深度特征提取之后输入噪声空间,并使用词嵌入技术嵌入文本提示词,在前空间内生成所需的图像后(低分辨率),通过去噪过程生成HR图像输出。
通常的操作是使用LH进行炼丹,同时输出多组低分辨率图像,得到所需要特征的图像后进行微调。微调过程可以通过局部重绘进行,也可使用LORA、embedding,外挂VAE等手段微调。